

昨天我們專注在 Label 與 Annotation。
Label 是 Kubernetes 世界的「身分證」,像是讓 Deployment 找到自己的 Pod、Service 能正確導流、Network Policy 指定要管制的對象。Annotation 則像是「便利貼」,補充背景資訊給人或外部工具參考。雖然 Label 與 Annotation 看似只是小細節,但其實是貫穿整個 Kubernetes 的基礎設計。
如果說昨天的 Label 幫我們建立了資源彼此的連結,那我們今天要來看看 Pod 與 Node 之間的關係。他同樣會大量依賴 Labels,因為 Pod 最後能不能被排進某台 Node,就靠這一套標籤系統來決定。畢竟「服務要跑起來」還不夠,要跑在對的地方才是真正的挑戰。
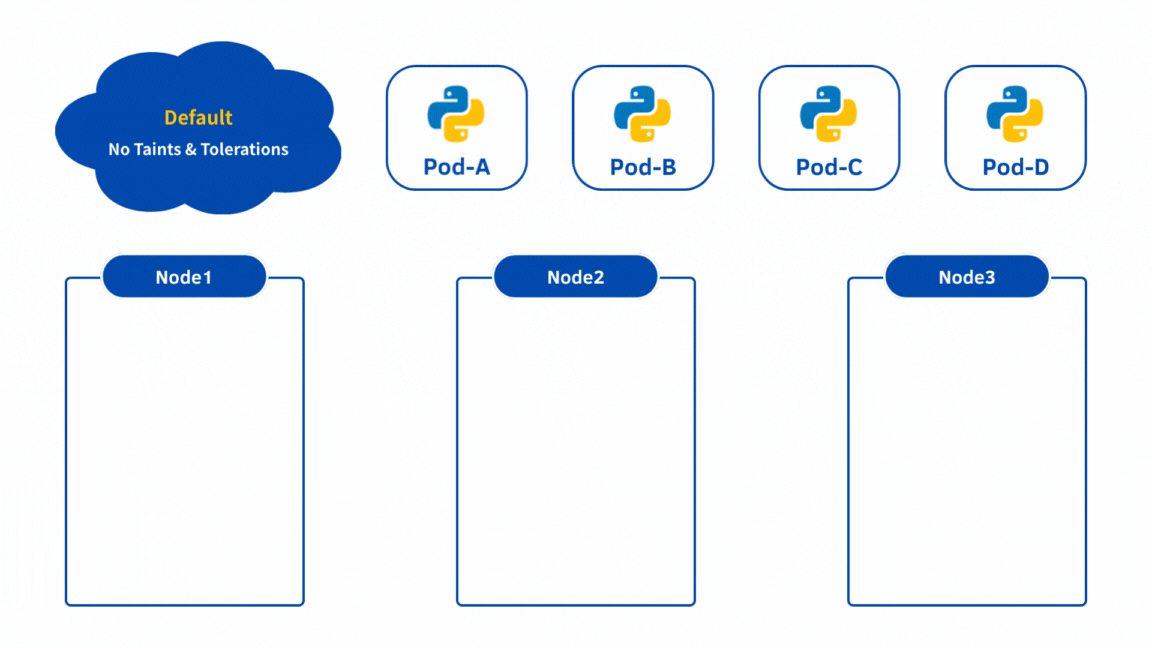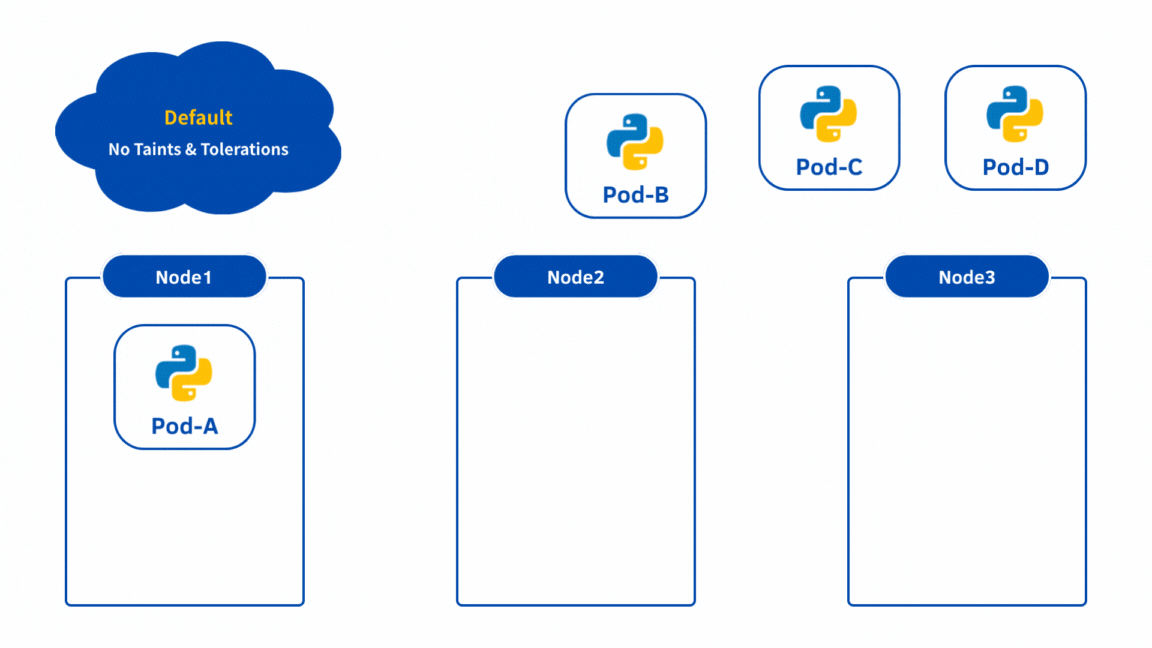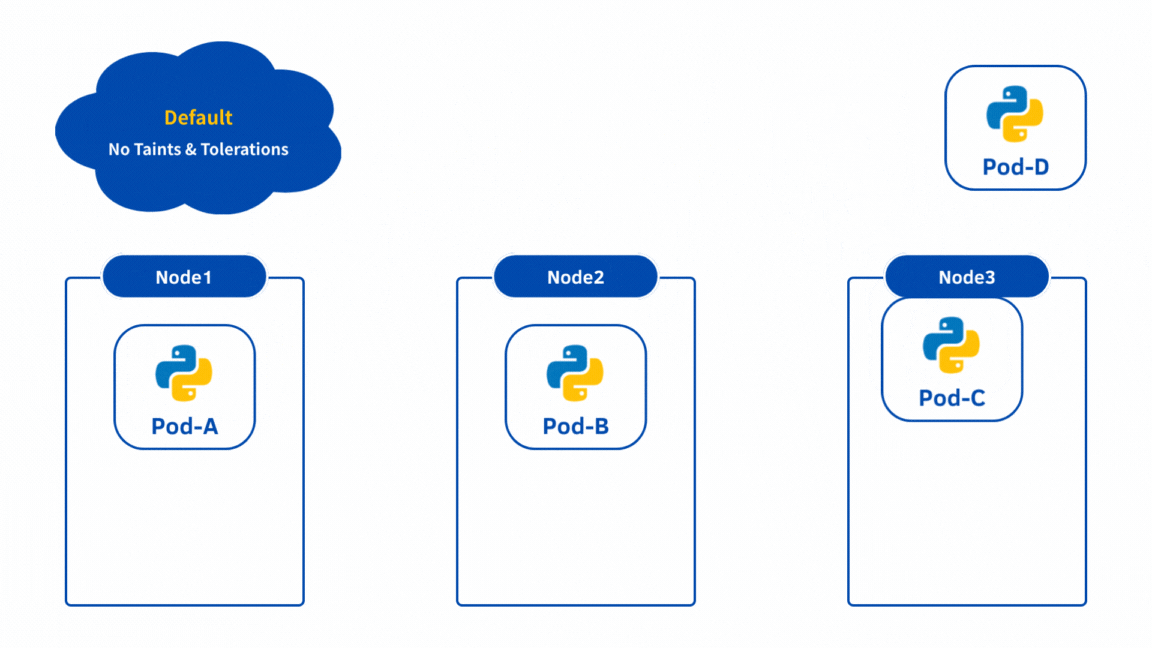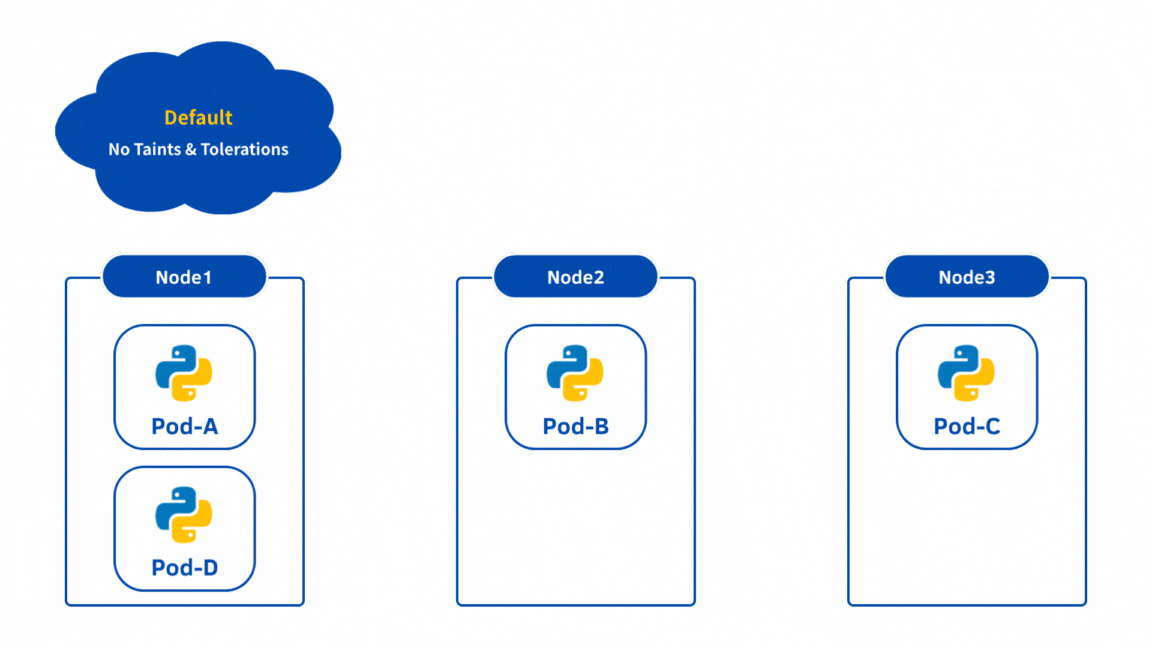
在沒有任何限制的情況下,Kubernetes Scheduler 會盡量把 Pod 平均分配到各個 Node 上。但在實務上並不是「公平分配」就好,因為不同的工作負載有不同需求:
因此我們需要機制來告訴 Kubernetes:哪些 Pod 可以去哪裡,哪些 Node 又該拒絕不相干的 Pod。這就是今天要來看看進行 Pod 調度的工具:Taints & Tolerations、Node Selector、Node Affinity
Node Selector 是最簡單的 Pod 調度方式,只要在 Node 上加上 labels 標籤:size=large,然後在 Pod 的配置加上 nodeSelector: size=large,這樣 Pod 就會被排到對應的 Node。
缺點是「只能單一條件」,若是要更複雜的規則,就要使用 Node Affinity。👇
Node Affinity 是進階版的 Node Selector,支援更多條件與運算子:
In:Pod 只能排到符合標籤值的 NodeNotIn:Pod 不排到特定標籤值的 NodeExists:Node 只要存在某個標籤即可DoesNotExist:Node 只要沒有某個標籤即可模式上分為:
未來還會有 requiredDuringExecution,代表如果 Node 標籤後來被改掉,不符合的 Pod 會直接被驅逐。
另外,除了針對 Node 的限制之外,還有一組類似的機制針對 Pod → Pod Affinity / Anti-Affinity。
基本語法和運算子與 Node Affinity 相同,也支援 required 與 preferred 這兩個硬性和軟性規則。
Taint(污點)是加在 Node 上的限制,Toleration(容忍度)則是加在 Pod 上的條件。預設 Pod 無法排到有 Taint 的 Node。只有帶有相對應 Toleration 的 Pod 才能「容忍」該 Taint,順利排進去。
比方說如上圖,我們把 Node1 留給 Blue 的應用程式:
Taint: Blue → 預設所有 Pod 都會被「彈開」Toleration: Blue
Taint 的效果分為三種:
👉 這也是為什麼 Master Node 預設就有一個 Taint(NoSchedule),防止一般工作負載被排到上面。
針對前面的三個規則他們有各自的痛點:
因此 兩者結合 才能做到雙向防護,既限制 Pod 不能亂跑,也限制 Node 不要亂收。
前面也有講到因為 Taints & Tolerations 不能保證 Pod 被安排到對應的 Node,因此我們先實戰 Node Selector 和 Node Affinity,再來看看 Taints & Tolerations 是怎麼擋下不應該進來的 Pod。
由於在 K8s 的最佳實踐中,Master Node 不會部署 Pod,因此我們這邊先看一下我們昨天幫 Worker Node1 和 Worker Node2 加上的 labels:
kubectl get nodes --show-labels

我們先看昨天加在 Node 上的標籤:Node1 是 env=dev,Node2 是 env=stage。
env=stage → 排進 Node2。env=dev → 排進 Node1。# Pod-A
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod-a
labels:
app: my-app-a
spec:
containers:
- name: nginx-container
image: nginx
nodeSelector:
env: stage
# Pod-B
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod-b
labels:
app: my-app-b
spec:
containers:
- name: nginx-container
image: nginx
nodeSelector:
env: dev

Pod-C 指定只能跑在 Node2:
# Pod-C
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod-c
labels:
app: my-app-c
spec:
containers:
- name: nginx-container
image: nginx
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: env
operator: In
values:
- stage

我把 Operator 換成 NotIn 的話,並且多加入一個 values -dev 上去:
# Pod-C
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod-c
labels:
app: my-app-c
spec:
containers:
- name: nginx-container
image: nginx
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: env
operator: NotIn
values:
- stage
- dev

我們可以看到處於 Pending 狀態,用 describe 來查看原因:

從這邊的訊息可以看到因為我們把 Node1 和 Node2 利用 Affinity 過濾掉,只剩下 Master Node 的選項。但因為 Master Node 的 Taint 的關係,因此也無法部署上去,導致 Pod 停留在 Pending 狀態。
Pod-D 測試 Exists Operator:
# Pod-D
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod-d
labels:
app: my-app-d
spec:
containers:
- name: nginx-container
image: nginx
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: test
operator: Exists


可以看到因為沒有任何的 Node 有 test 這個 labels,因此也是處在 pending 的狀態。

我們幫 Node1 加上 test label 之後,Pod-D 就成功部署上去了。
接下來我們看到 Pod Affinity,我們 Pod-A 的配置還是跟上面一樣:

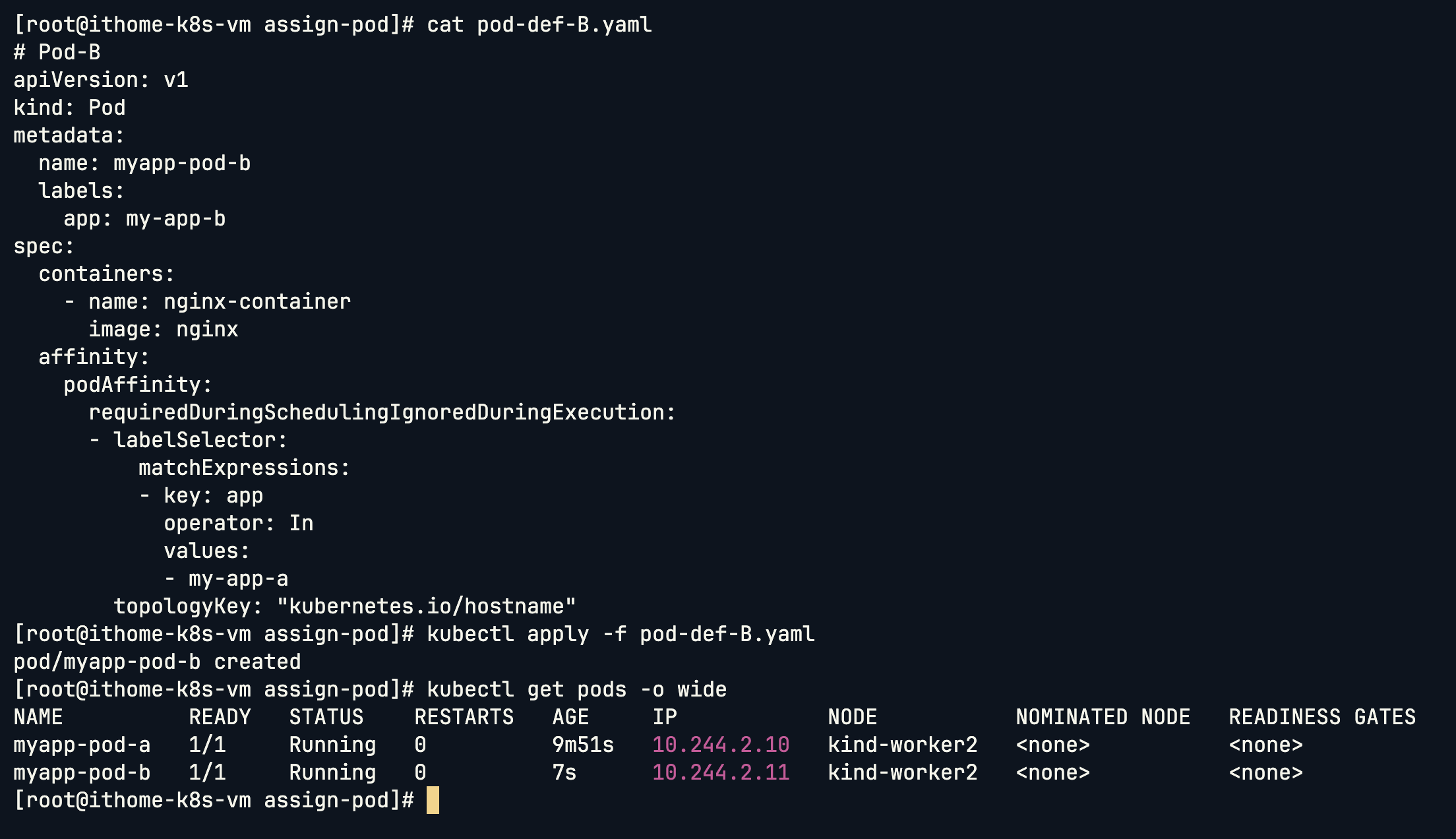
我希望 Pod-B 可以跟 Pod-A 部署在同一個 Node,這時候可以用到 Pod Affinity:
# Pod-B
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod-b
labels:
app: my-app-b
spec:
containers:
- name: nginx-container
image: nginx
nodeSelector:
env: dev
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- my-app-a
topologyKey: "kubernetes.io/hostname"
topologyKey 典型的值是 Node 的 label key。
- 最常見的是:
kubernetes.io/hostname→ 限制在相同節點 / 不同節點。topology.kubernetes.io/zone→ 限制在相同可用區 (AZ)。topology.kubernetes.io/region→ 限制在相同區域。
可以看到因為我們希望 Pod-A 和 Pod-B 要在同一個 Node,但是我們的 Node Selector 是指定不同的,導致 Pod 停留在 Pending 狀態。


移除 Node Selector 之後 Pod-A 和 Pod-B 就成功的被部署在同一個 Node:
實戰的部分我們都直接沿用上面的範例,我們要對 Node1 加上 Taint: Blue,然後只有 Pod-D 可以部署在 Node1。
kubectl taint nodes kind-worker app=blue:NoSchedule

這邊可以看到我們的 Node1 (kind-worker) 因為已經設置 Taints,當我們要部署 Pod-D 時可以看到被 app: blue 的 taints 給擋下來了。

因此我們幫 Pod-D 加上 Toleration:
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod-d
labels:
app: my-app
type: front-end
spec:
containers:
- name: nginx-container
image: nginx
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: env
operator: In
values:
- dev
tolerations:
- key: "app"
operator: "Equal"
value: blue
effect: NoSchedule
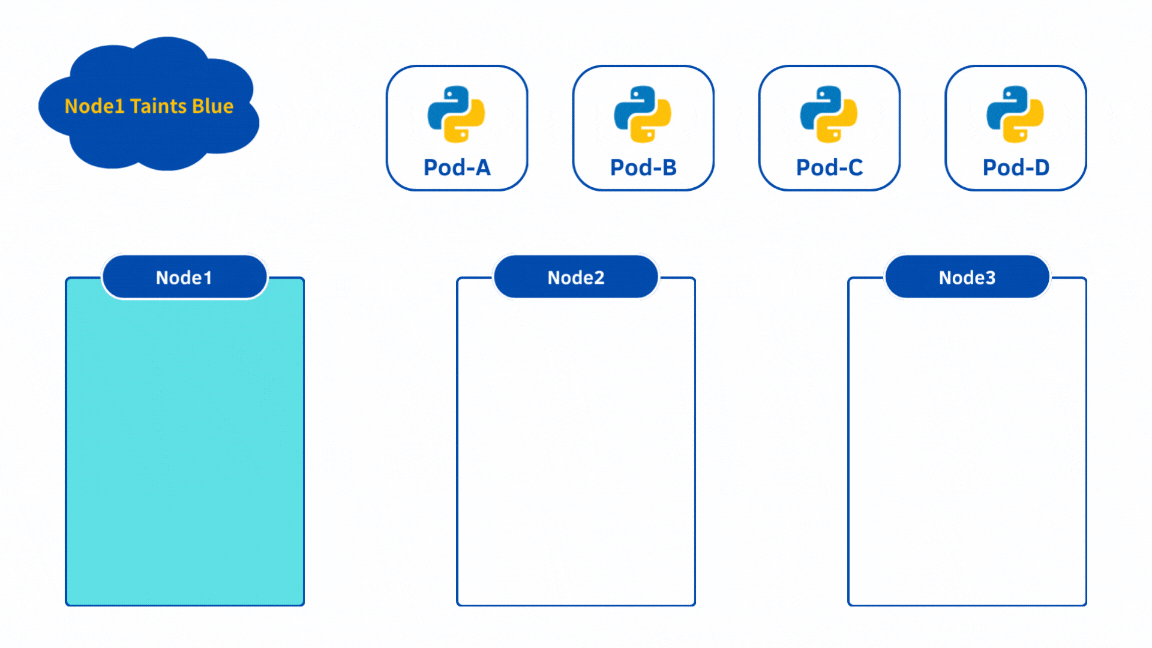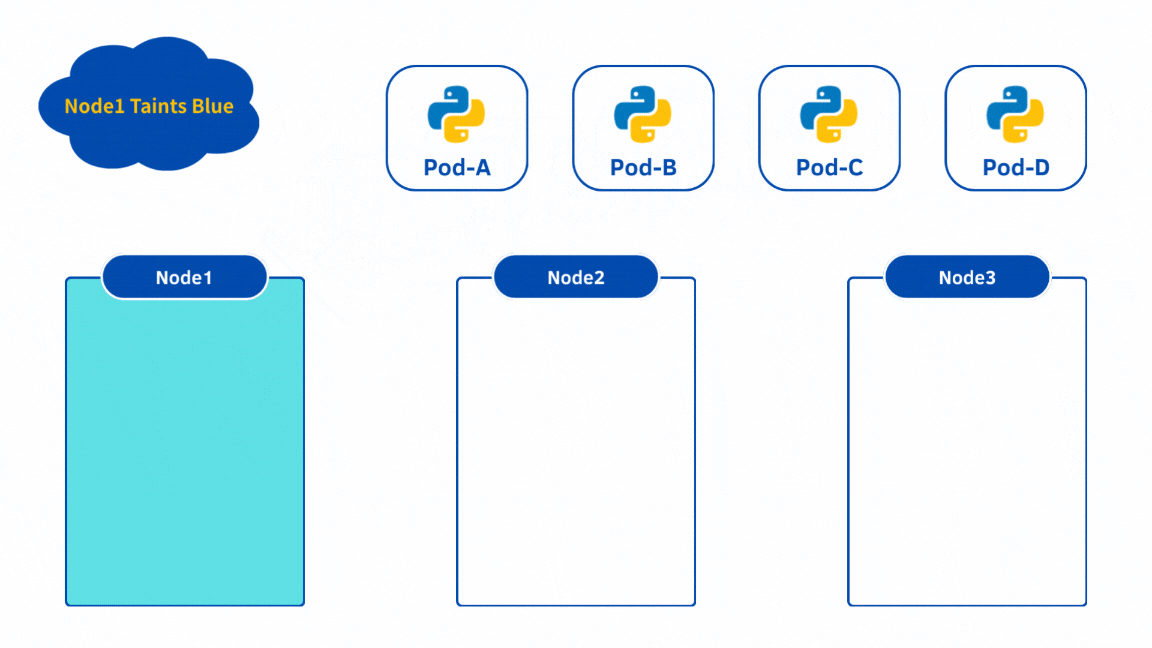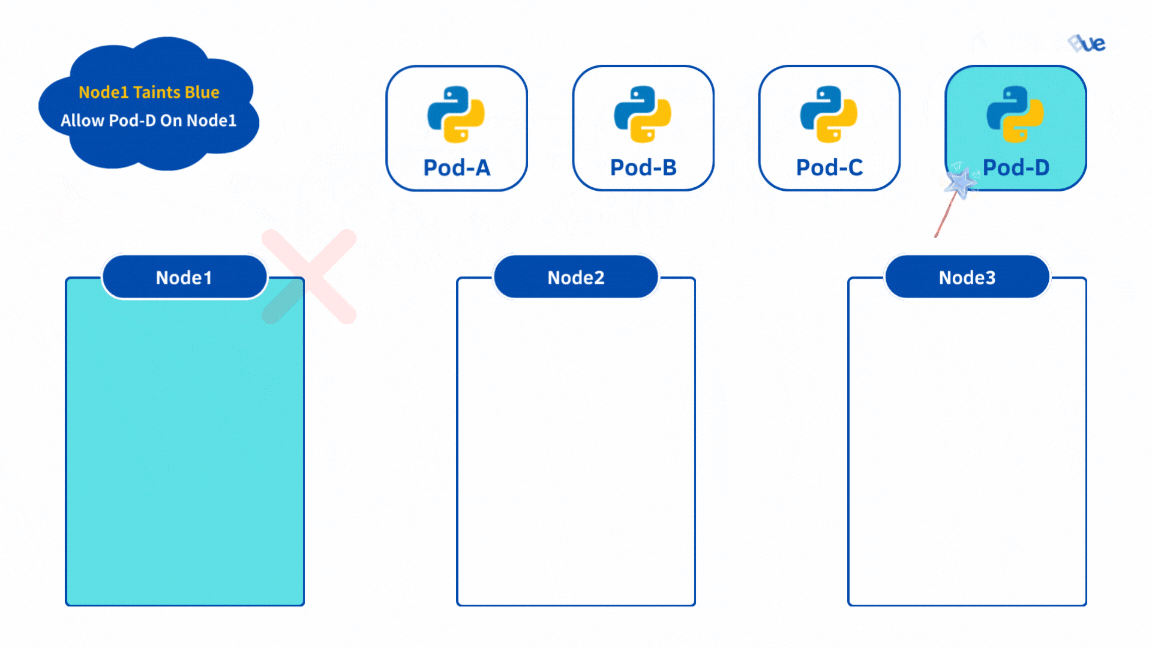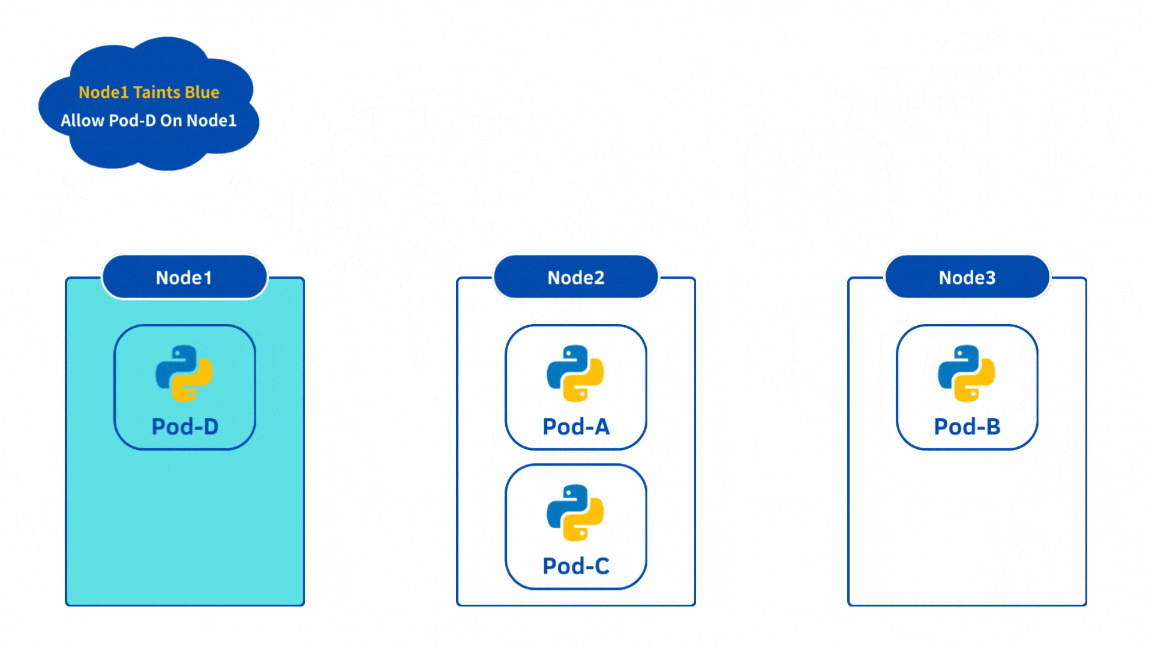
Pod-D 成功部署到 Node1 上面了!

今天我們看了 Kubernetes 調度策略的幾種主要方式。從最簡單的 Node Selector 開始,它像是一種快速的指定工具,能直接把 Pod 對應到帶有標籤的 Node;再到 Node Affinity,它提供了更靈活的語法,能設定硬性或軟性的條件,甚至用不同的運算子去過濾或挑選節點。進一步的 Pod Affinity 與 Anti-Affinity,則讓我們能針對 Pod 與 Pod 的關係來決定要不要部署在一起。最後則是 Taints & Tolerations,它從 Node 的角度反向控制哪些 Pod 可以進來,透過雙方搭配才能真正達到「該上的能上,不該上的不能上」。這些工具彼此之間不是替代關係,而是互補關係,要靈活的組合使用,才能在複雜的實際生產環境中,讓 Pod 被調度到最合適的位置。
| 機制 | 作用對象 | 特性 | 常見用途 |
|---|---|---|---|
| Node Selector | Node | 單一條件,簡單快速 | 指定 Pod 到特定環境(如 dev/stage) |
| Node Affinity | Node | 支援複雜規則(In, NotIn, Exists 等),可硬性/軟性限制 | 控制 Pod 分布到符合標籤的節點 |
| Pod Affinity / Anti-Affinity | Pod | 控制 Pod 與 Pod 的相對位置 | 相依服務部署在一起,或避免放同一 Node |
| Taints & Tolerations | Node + Pod | Node 拒絕 Pod,Pod 需加 Toleration 才能進入 | 保護特定節點,只允許指定工作負載進入 |
當我們掌握了「Pod 該放在哪裡」之後,接下來要看的就是「Pod 該什麼時候執行」。這就是 Job 與 CronJob 的世界——我們將看到如何控制工作負載的執行時機,無論是一次性任務還是週期性排程,Kubernetes 都能幫我們自動化完成。
